Previsioni di borsa
Andrea Murru | 14 Marzo 2014Se un investitore azzecca sei volte su dieci è bravo.
Se azzecca sette volte su dieci è molto bravo e fortunato.
Se azzecca otto volte su dieci è bugiardo.
Warren Buffett
Mentre facevo un po’ di pulizia sull’HD, ieri mi sono imbattuto in una cartella che conteneva la mia tesi di laurea.
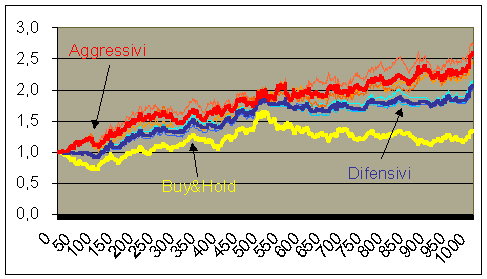
Devo dire che non mi ricordavo di averci fatto tanto lavoro! E neppure di aver affrontato tanti argomenti d’interesse, pure abbastanza attuali. Mi piace in particolare l’attenzione dedicata alla significanza dei risultati ottenuti, con considerazioni decisamente apprezzabili anche dopo tanto tempo.
Interessante anche il lavoro di programmazione, codice sorgente decisamente ben strutturato, considerando la complessità di alcune implementazioni (come le reti neurali localmente ricorrenti e tutta la parte degli algoritmi genetici).
Insomma, non nego che mi abbia fatto venire un po’ di voglia di riprendere in mano la questione … se qualcuno è interessato i sorgenti e tutta la documentazione, sono a disposizione!
Nel frattempo, potete dare un’occhiata alla presentazione (utile per farsi un’idea) oltre che alla tesi vera e propria.
- Comments
- Nessun Commento »
- Categorie
- Finanza, Programmazione
- Tags
- algoritmi genetici, borsa, NXCS, reti neurali
 Commenti RSS
Commenti RSS  Trackback
Trackback



